
Ethics statement
This study adhered to the principles of the Declaration of Helsinki and was approved by the Institutional Review Board of Kangwon National University Hospital (KNUH-2023-01-011), which waived the requirement for obtaining informed consent due to the retrospective nature of the observational study of medical records. This study was retrospectively registered.
Data collection
We enrolled patients aged ≥ 18 years undergoing hemodialysis in Kangwon National University Hospital between 2017 and 2022. During this period, five nephrology experts prescribed medications, including ESAs. The patients analyzed in this study received only darbepoetin-alfa among several ESA types. In addition, data were retrospectively collected from inpatient and outpatient clinics.
Information regarding the following clinical variables was obtained: demographic characteristics, dialysis, drug use, laboratory tests, and transfusion. The demographic data included sex, age, and total dialysis progression date. Dialysis data encompassed systolic blood pressure, diastolic blood pressure, and pulse rate, measured every hour during dialysis, along with the dry weight and total ultrafiltration volume. The drug categories included ESAs, oral iron, and intravenous iron. Laboratory test data included: Hb level; white blood cell count; platelet count; and levels of blood urea nitrogen, creatinine, sodium, potassium, chloride, uric acid, total calcium, phosphorus, intact parathyroid hormone, glucose, total protein, albumin, aspartate aminotransferase, alanine aminotransferase, alkaline phosphatase, total cholesterol, triglyceride, high-density lipoprotein, iron, total iron-binding capacity, ferritin, hepatitis B surface antigen, hepatitis B surface antibody, and hepatitis C antibody. Finally, in the transfusion category, we only collected RBC transfusion data.
Data preprocessing
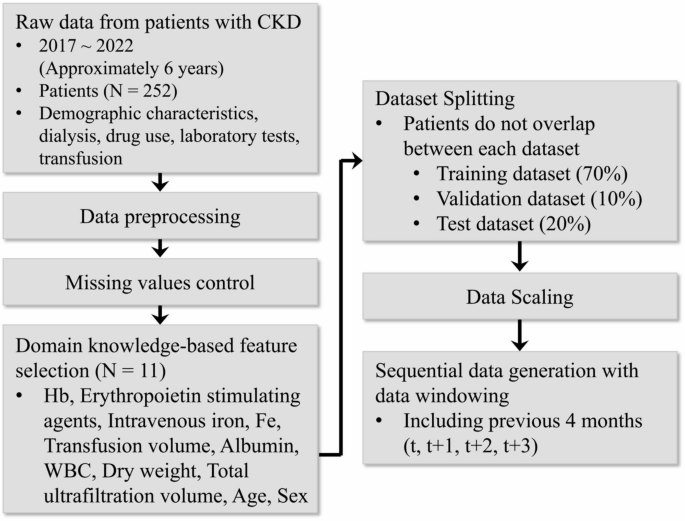
Demographic, dialysis, drug use, laboratory test, and transfusion data were initially collected from 829 patients. Following data collection, meticulous data refinement was conducted based on the inclusion and exclusion criteria. Patients with < 3 months of data were excluded to ensure a comprehensive understanding of individual clinical changes over time. Additionally, only patients who underwent dialysis sessions from 3 h 30 min to 4 h 30 min, reflecting typical dialysis scenarios, were included in the dataset. Ultimately, a dataset comprising 252 patients was constructed, as shown in Fig. 1.
Overview of the data preparation process. Commencing with the basic preprocessing of hemodialysis patient data spanning approximately 6 years, we utilized clinical knowledge to select relevant features. Following this, the dataset was partitioned into the training, validation, and test sets, which were then scaled appropriately. Finally, the data were transformed into a sequential data format suitable for analysis. CKD, chronic kidney disease; Hb, hemoglobin; WBC, white blood cell.
The ESA dose used for training and validating the ESA dose recommendation model and the transfusion alarm model is calculated as the total dose prescribed for the given month. In other words, the ESA dose is treated as a single variable. For instance, the ESA dose for May in a patient who undergoes hemoglobin testing on the 13th of each month is the total amount of ESA prescribed from April 13 to May 12. The ESA dose on the prescription date is excluded since blood draws for hemoglobin testing are generally conducted before the ESA prescription.
The dataset used for training is organized based on patient-months, which correspond to the dates when patients undergo hemoglobin tests. Typically, hemoglobin tests are conducted once a month. Since not all patients are tested on the same date, the monthly data is structured according to each patient’s individual test date. In some cases, if a patient’s condition worsens or there is a special reason, an additional test may be performed before an entire month has passed since the previous test. The additional test results are excluded in such cases, and only the regular hemoglobin test results are used.
Variables with missing values exceeding 15% of the entire dataset were removed, whereas those with missing values below 15% were addressed through imputation using preceding values from the same patient. A label-encoding method was employed for categorical data, facilitating a streamlined analysis across consistent categories.
Model architecture
We introduced GAM to effectively capture historical information from the data of patients undergoing chronic hemodialysis while simultaneously focusing on critical information within a relatively short timeframe. The GRU18 exhibits computational efficiency and effectiveness in handling time-series data. Additionally, the integration of a multi-head attention mechanism19 empowers the discernment of interrelationships among the data within the same window.
The overall architecture of GAM is depicted in Fig. 2. Initially, patient data, including demographics, dialysis, drug use, laboratory tests, and transfusions, were fed into the GRU and attention modules. Patient data was entered into the GRU units sequentially, resulting in hidden states cascading to the subsequent GRU units, thereby capturing sequential information. Simultaneously, patient data were inputted into the attention module to extract essential details within the current window. The extracted information was then concatenated to form the final patient embedding that encapsulated the patient’s historical data. In this context, \(\:x\left(0\right)\), \(\:t\), and \(\:h\) denote the first data point within the current window, window size, and hidden state, respectively, with the initial hidden state set to a random value.

Overall architecture of the proposed model (GRU-attention-based module; GAM). Patient data, including demographic characteristics, dialysis, drug use, laboratory tests, and transfusion, were input simultaneously into the gated recurrent unit (GRU) and multi-head attention module. The GRU captures a patient’s long-term condition, whereas the multi-head attention module captures essential information about state changes. These two datasets are combined to create a patient embedding containing historical information.
The generated patient embedding encapsulates rich historical information on patients undergoing chronic hemodialysis. The process of leveraging this embedding to forecast Hb levels is illustrated in Fig. 3. Similar to the previously described methodology, GAM utilizes time-series data encompassing Hb levels, ESA doses, and other supplementary data from time points t to t + 3 to generate the patient embedding. Subsequently, the resultant embedding is fed into the input of the Hb predictor, which consists of fully connected and dropout layers, ultimately predicting the Hb levels at time point t + 4.

The framework of hemoglobin (Hb) level prediction process. At first, the gated recurrent unit (GRU)-attention-based module (GAM) network is used to process sequential data from patients, generating patient embedding. Following this, prediction of the Hb level for the next time point is carried out using fully connected and dropout layers. CKD, chronic kidney disease; ESA, erythropoiesis-stimulating agent.
ESA dose recommendation and transfusion alarm framework
The overall framework for conducting the ESA dose recommendation and transfusion alarm tasks is illustrated in Fig. 4. Unlike the Hb prediction task, patient data ranging from time points t to t + 2 were entered into the GAM network to construct the patient embedding. The resulting embedding was combined with patient data at time point t + 3, encompassing Hb levels, transfusion volume, and supplementary data. Importantly, the optimal Hb level at time point t + 4 was also incorporated at this stage.

The framework of erythropoiesis-stimulating agent (ESA) dose recommendation and transfusion alarm process. Patient data from time points t to t + 2 passes through the gated recurrent unit (GRU)-attention-based module (GAM) network, generating patient embeddings. Subsequently, the hemoglobin (Hb) level, transfusion volume, and supplementary data at t + 3 are combined with the optimal Hb level data at t + 4, followed by the application of a fully connected layer and dropout. The outcomes for the ESA dose recommendation task are categorized as “more,” “similar,” and “less,” whereas the transfusion alarm task provides results indicating “necessary” or “non-necessary.” CKD, chronic kidney disease.
Our primary goal was to maintain the patient’s Hb level within the normal range by utilizing the ESA dose recommendation and transfusion alarm. To achieve this, we introduce an approach wherein, instead of employing the actual t + 4 Hb level, we inputted information about the ideal Hb level that would be adjusted through ESA administration and transfusion. This approach enabled the model to appropriately recommend the ESA dose and identify when transfusion is needed. The optimal Hb level corresponded to the same time point as that for the ESA dose recommendation and transfusion alarm (t + 4). The optimal Hb level was adjusted based on the Hb level at time point t + 3, as described in Eq. 19:
$$\:{\widehat{y}}_{hb}^{t+4}=\:\left\{\begin{array}{ll}{y}_{hb}^{t+3}+1,&if\:{y}_{hb}^{t+3}<10\\\:11,& otherwise\\\:{y}_{hb}^{t+3}-1,& if\:{y}_{hb}^{t+3}>12\end{array}\right.$$
(1)
The notation \(\:{\widehat{y}}_{hb}^{t+4}\) represents the optimal Hb level at time point t + 4. If the Hb level was < 10, \(\:{\widehat{y}}_{hb}^{t+4}\) was set as \(\:{y}_{hb}^{t+3}\) + 1. If the Hb level exceeded 12, \(\:{\widehat{y}}_{hb}^{t+4}\) was calculated by subtracting 1 from \(\:{y}_{hb}^{t+3}\). For cases outside these ranges, \(\:{\widehat{y}}_{hb}^{t+4}\) was set to 11. According to the Kidney Disease Outcomes Quality Initiative (KDOQI) guideline20, the optimal hemoglobin level is 11 g/dL or more but does not exceed 13 g/dL, whereas the Kidney Disease Improving Global Outcomes (KDIGO) guidelines recommend a level of 10–11.5 g/dL6. Given that insurance covers ESAs only up to a Hb level of 11 g/dL in South Korea, this formula was established. Subsequently, patient embedding was concatenated with the patient data at time point t + 3 and the optimal Hb level at time point t + 4. This concatenated information was then processed through fully connected and dropout layers.
The ESA dose recommendations were categorized into three groups: more, similar, and less, indicating whether a higher, similar, or lower ESA dose should be prescribed for the subsequent month (t + 3) compared to that in the previous month (t + 2). It is important to note that each patient’s response to ESA varies; therefore, it can be sensitive to even small changes in the ESA dose, and the effect may be slow even if a relatively large amount of ESA is administered. To accommodate such variations, the “similar” category considered doses within ± 25% of the ESA dose prescribed in the previous month (t + 2). The transfusion alarm outputs “necessary” if transfusion is deemed necessary to reach the optimal Hb level based on patient data from time point t to t + 3. Conversely, it outputs “non-necessary” if transfusion is deemed unnecessary.
Experimental setup
Following the description provided in the latter part of Fig. 1, the training, validation, and test datasets were partitioned into ratios of 0.7, 0.1, and 0.2, respectively, to ensure that there were no overlapping patients across datasets. Subsequently, each variable was standardized by transforming it to a mean of 0 and a standard deviation of 1. The variables were reshaped into sequential configurations and aligned with the input requirements of the proposed model. The selected window size for this transformation was established as 4, based on the findings derived from the experimental outcomes presented in Appendix Table 2. The final structure of the input data was organized as (data_num, window_size, feature_num).
To train the proposed model, we set the following parameters: 500 epochs, batch size of 128, learning rate of 0.0005, and dropout rate of 0.5. The chosen optimizer was Adam, and the loss function applied was categorical cross-entropy. Early stopping was implemented during model training to efficiently manage the computing resources and reduce unnecessary resource usage. The model with the best performance was selected for subsequent analyses.
In the experiments outlined in Table 1, the epoch, batch size, and learning rate were set to 500, 128, and 0.003, respectively. For XGBoost, the n_estimator was set to 500. In the case of the MLP, the Adam optimizer was used, with a dropout rate of 0.6. Adam was also adopted as the optimizer for the LSTM but with a dropout rate of 0.5. All hyperparameters were determined through parameter tuning to achieve optimal performance.
To assess the predictive capabilities for Hb levels, linear regression, XGBoost13, and MLP were used as conventional machine learning benchmarks. Furthermore, to assess the capacity to incorporate temporal dependencies intrinsic to sequential data from patients undergoing chronic dialysis, we incorporated LSTM, a variant of the RNN, and the GRU architecture, which are the Hb prediction models previously proposed by Yun9. Specifically, we used the original GRU model denoted as “GRU architecture (A)” and another variant denoted as “GRU with GNR (Baseline).”
Statistical analysis
The Hb level prediction task was considered a regression problem, and its performance evaluation utilized the following four metrics: R-squared, MSE, RMSE, and MAE. Conversely, in the context of the ESA dose recommendation and transfusion alarm tasks, which are considered classification problems, the evaluation metrics included precision, recall, F1-score, and accuracy. Experiments were conducted using Keras with a TensorFlow backend.
 Arabic
Arabic Chinese (Simplified)
Chinese (Simplified) Dutch
Dutch English
English French
French German
German Italian
Italian Portuguese
Portuguese Russian
Russian Spanish
Spanish